Ollama context at generate API output — what are those numbers?
Background
Given I have access to an M1 Mac Mini, I have been looking for ways to run some Large Language Model (LLM) on that as a locally run LLM and test out some idea.
So happen I see Ollama, which is a very handy project that allow one running Llama 2 and other models derived from Llama 2 (I believe it is … or at least from Llama…)
The great thing about the Ollama project is it’s very easy to setup at Mac (as an App and with CLI), and it expose some API to manage the model and perform “conversation” (generation of response)
Some architecture stuff
My Mac Mini is running in office, behind a network that I have no control (like fixed IP kind, opening of port…), so throughout the process, I would be using tunneling to expose the API.
The tunneling package I use it localtunnel, pretty handy, we can specify which port we want to expose and it create a URL (with SSL cert) you can use over the internet to access the port, the down side is it “expire” after some time and one need to run the command to expose again (with a different URL)
The Ollama generate response API
According to the API doc, the generate API goes like this:
The context as conversation memory?
Given some other LLM (like ChatGPT) does not have any kind of memory, the whole conversation history need to be repeatedly input to the LLM to “continue” the conversation (which is just “completion”), I do wonder how this works.
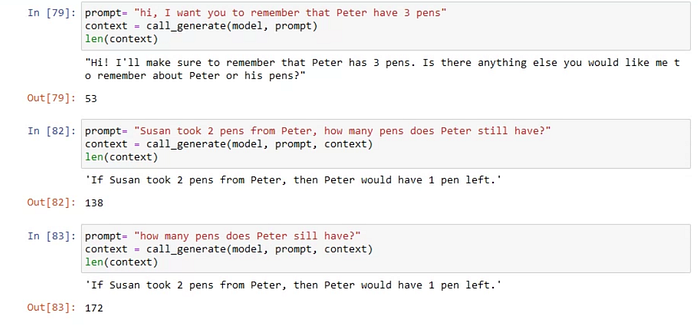
So I tested it with something like this simple:

So I capture the context at some point and use it to “branch” different conversation and it looks like it does follow the context that captured the “memory”.
Let’s focus on the response of the /generate API call, it’s some ndJSON, which are JSON separated by \n.

And the very last piece of response look like this:
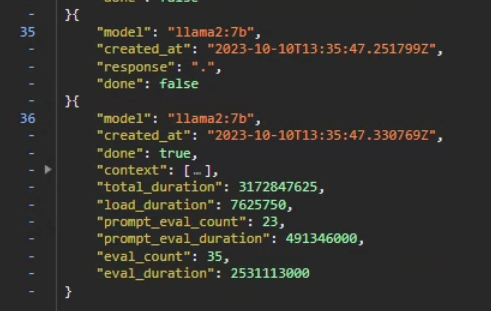
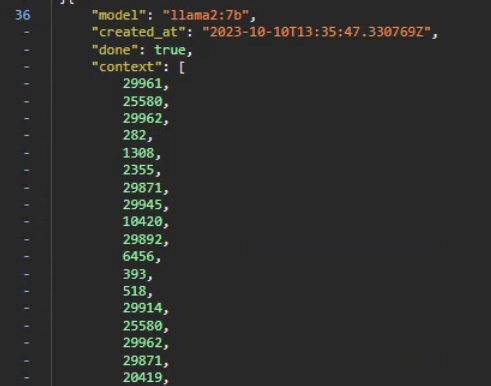
The interesting thing is, the length of context is not fixed tensor (Llama 2 should be having a 4096 size embedding), and this “context” keep growing when we continue the conversation, this make me wonder what is inside.
The code inspection
It’s always good to read the source code to know what happened underneath some behavior, after some digging, from the Ollama server (that serve the generate API), checking the handler and seeing the call to Llama model, finally saw this:
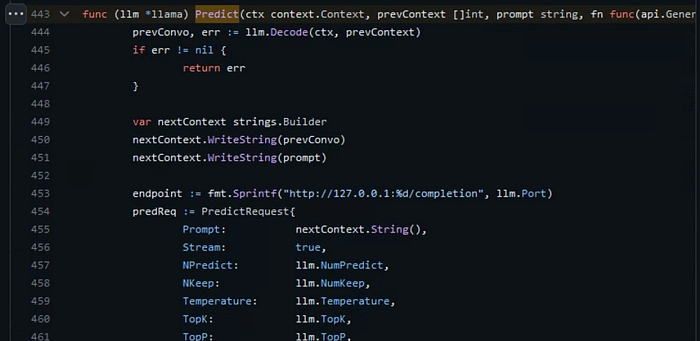
And then look at the Decode function that process the prevContext:
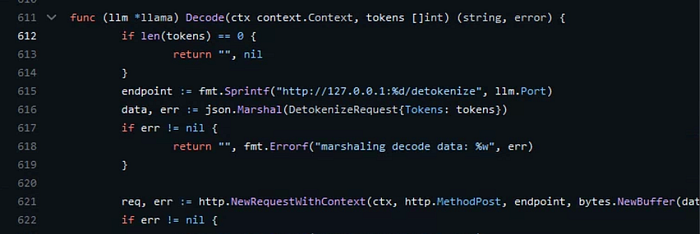
Here we see it call a /detokenize API which point to llm.port, which is NOT the Ollama’s exposed 11434 port.
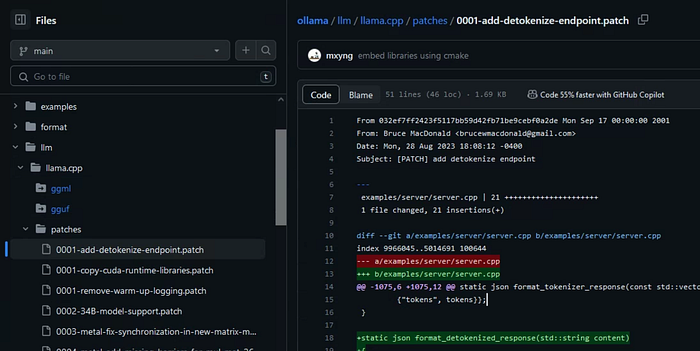
This is actually a customized llama.cpp server, and one of the customization is exposing /detokenize API
This llama.cpp is not always loaded in memory, it would expire after some time when we interact with the server, and it would load every time with a random port:
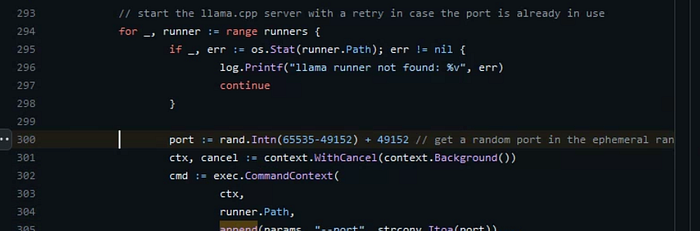
So using lsof to check openned port:
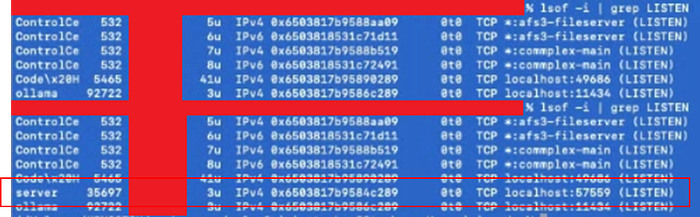
An trying access it (another localtunnel…), and here what we see — the llama.cpp custom server
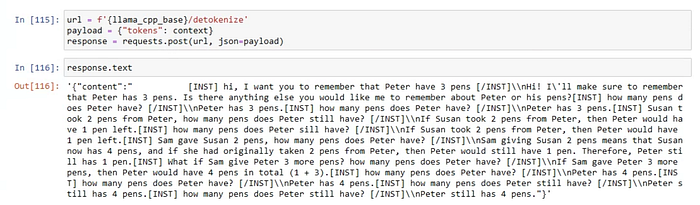
What is the context after all?
After all, what the customized llama.cpp /detokenize API does is to decode the vector back into the whole message history:
Conclusion
So there is no magic after all, but the idea of encode the whole history and decode it back is a nice idea, and Ollama is a good package / solution that allow us prototype idea quick and easy, I would say I appreciate it alot.
